
De negen bouwstenen achter vrijwel elk modern AI-systeem
Van chatbots tot multimodale assistenten: onder de motorkap van moderne AI draait alles om een vaste set technische principes. Tokenization, embeddings, transformers en fine-tuning vormen samen de ruggengraat van vrijwel elk hedendaags model. Wie deze kernconcepten begrijpt, kan sneller door whitepapers, productdocumentatie en AI-aankondigingen navigeren. Dit overzicht brengt structuur in de architectuur van artificiële intelligentie.
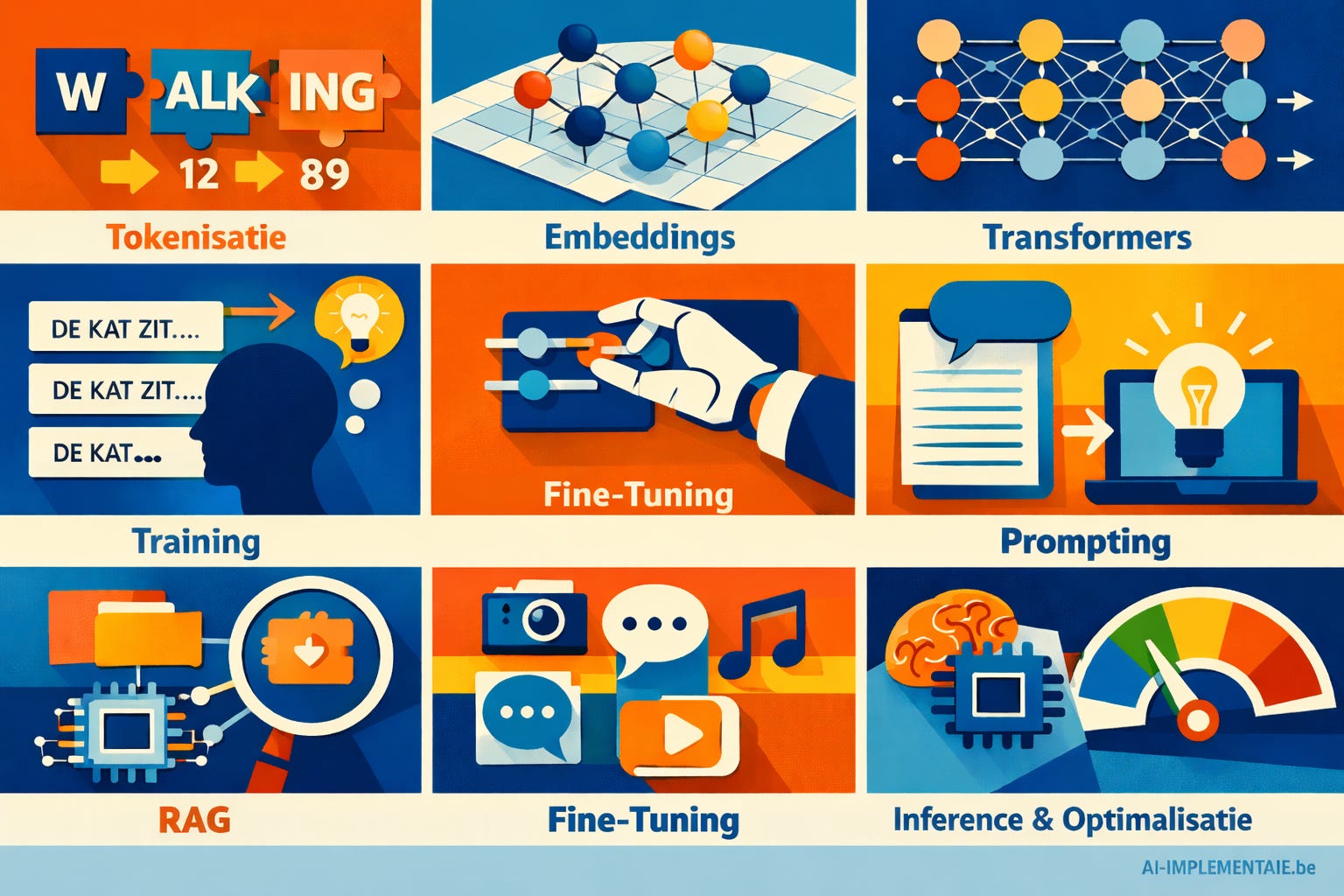
AI-systemen ogen vaak indrukwekkend en complex, maar hun fundament is verrassend consistent. Ongeacht of het gaat om een taalmodel, beeldgenerator of slimme zoekmachine, de onderliggende architectuur steunt meestal op dezelfde kernideeën. Dit zijn de negen belangrijkste.
1. Tokenization: taal reduceren tot data
Neurale netwerken kunnen geen ruwe tekst verwerken. Daarom wordt elke zin eerst opgesplitst in kleinere eenheden, zogenaamde tokens. Elk token krijgt een unieke numerieke identificatie.
Een gangbare techniek is Byte Pair Encoding (BPE). Die methode vertrekt van individuele tekens of bytes en combineert veelvoorkomende patronen tot grotere segmenten. Zo kan een woord als “walking” worden gesplitst in “walk” en “ing”. Het eindresultaat is een reeks getallen waarmee het model kan rekenen.
2. Embeddings: betekenis in vectorruimte
Na tokenization worden tokens omgezet in vectoren: numerieke representaties die semantische betekenis bevatten.
In deze zogeheten embeddingruimte liggen woorden met een gelijkaardige betekenis dicht bij elkaar. “Hond” en “kat” bevinden zich bijvoorbeeld dichter bij elkaar dan “hond” en “vliegtuig”. Dankzij embeddings kan een model betekenis mathematisch interpreteren en vergelijken.
Ze vormen de basis voor semantisch zoeken, aanbevelingssystemen en kennisopvraging.
3. Transformers: de standaardarchitectuur
De echte doorbraak in moderne AI kwam er met de introductie van de transformer-architectuur door Google Brain in 2017.
Transformers maken gebruik van self-attention, een mechanisme dat elk woord in relatie plaatst tot alle andere woorden in dezelfde context. Daardoor begrijpen modellen beter hoe zinsdelen samenhangen, zelfs over langere afstanden.
Vandaag zijn vrijwel alle large language models (LLM’s) op deze architectuur gebaseerd.
4. Leren via voorspelling
De trainingsmethode van taalmodellen is in essentie eenvoudig: ze leren door het volgende token te voorspellen.
Het model krijgt enorme hoeveelheden tekst voorgeschoteld en probeert telkens te raden welk woord of token volgt. Op basis van fouten past het zijn interne parameters aan. Door dit proces miljarden keren te herhalen, leert het statistische patronen in taal herkennen.
5. Fine-tuning: van algemeen naar gespecialiseerd
Na een brede pretraining worden modellen vaak verder verfijnd via fine-tuning. Daarbij worden ze afgestemd op specifieke taken, zoals samenvatten, vertalen of programmeren.
Een veelgebruikte techniek is reinforcement learning from human feedback (RLHF), waarbij menselijke beoordelaars verschillende outputs rangschikken. Het model leert zo welke antwoorden kwalitatief beter zijn.
Dit maakt AI-systemen bruikbaarder en beter afgestemd op menselijke verwachtingen.
6. Prompting: de nieuwe gebruikersinterface
Waar klassieke software knoppen en menu’s gebruikt, werken taalmodellen via prompts: tekstuele instructies die richting geven aan de output.
De manier waarop een vraag wordt geformuleerd, beïnvloedt sterk het resultaat. Prompt engineering is daardoor een belangrijk onderdeel geworden van AI-gebruik in professionele contexten.
7. Retrieval Augmented Generation (RAG)
Veel moderne systemen combineren generatieve modellen met externe databronnen. Via Retrieval Augmented Generation (RAG) haalt het systeem eerst relevante documenten op, die vervolgens worden meegenomen in de generatie van het antwoord.
Dit vermindert hallucinaties en verhoogt de betrouwbaarheid, vooral in zakelijke toepassingen waar actuele of gecontroleerde informatie cruciaal is.
8. Multimodaliteit: meerdere vormen van input
AI evolueert steeds vaker naar multimodale systemen die tekst, beeld, audio en video combineren.
Door verschillende modaliteiten in één gedeelde representatie te verwerken, kunnen modellen bijvoorbeeld afbeeldingen beschrijven, gesproken taal transcriberen of tekst omzetten in beeld. Deze integratie markeert een volgende fase in generatieve AI.
9. Inference en optimalisatie
Na de trainingsfase komt inference: het moment waarop het model in productie wordt gebruikt om realtime antwoorden te genereren.
Hier ligt de focus op efficiëntie. Technieken zoals quantization en modeldistillatie verkleinen modellen of maken ze sneller, zodat ze economisch inzetbaar blijven in cloudomgevingen of zelfs op lokale apparaten.
Complex, maar niet mysterieus
Hoewel AI-systemen indrukwekkend ogen, rust hun werking op een beperkt aantal herhaalbare principes. Door tokenization, embeddings, transformers en optimalisatietechnieken te begrijpen, wordt duidelijk hoe chatbots, zoekmachines en multimodale assistenten functioneren.
Wat op het eerste gezicht revolutionair lijkt, blijkt onder de motorkap vooral een slimme combinatie van robuuste, schaalbare bouwstenen.