
Evals bepalen of een AI-agent klaar is voor de praktijk
Een werkende AI-demo is nog geen betrouwbaar product. De echte test begint wanneer teams moeten aantonen dat een agent consistent correcte, nuttige en gepast geformuleerde resultaten levert. Systematische evaluaties, of evals, vormen daarom de ruggengraat van elke serieuze AI-workflow. Ze tonen niet alleen aan of een systeem werkt, maar ook waar en waarom het misloopt.
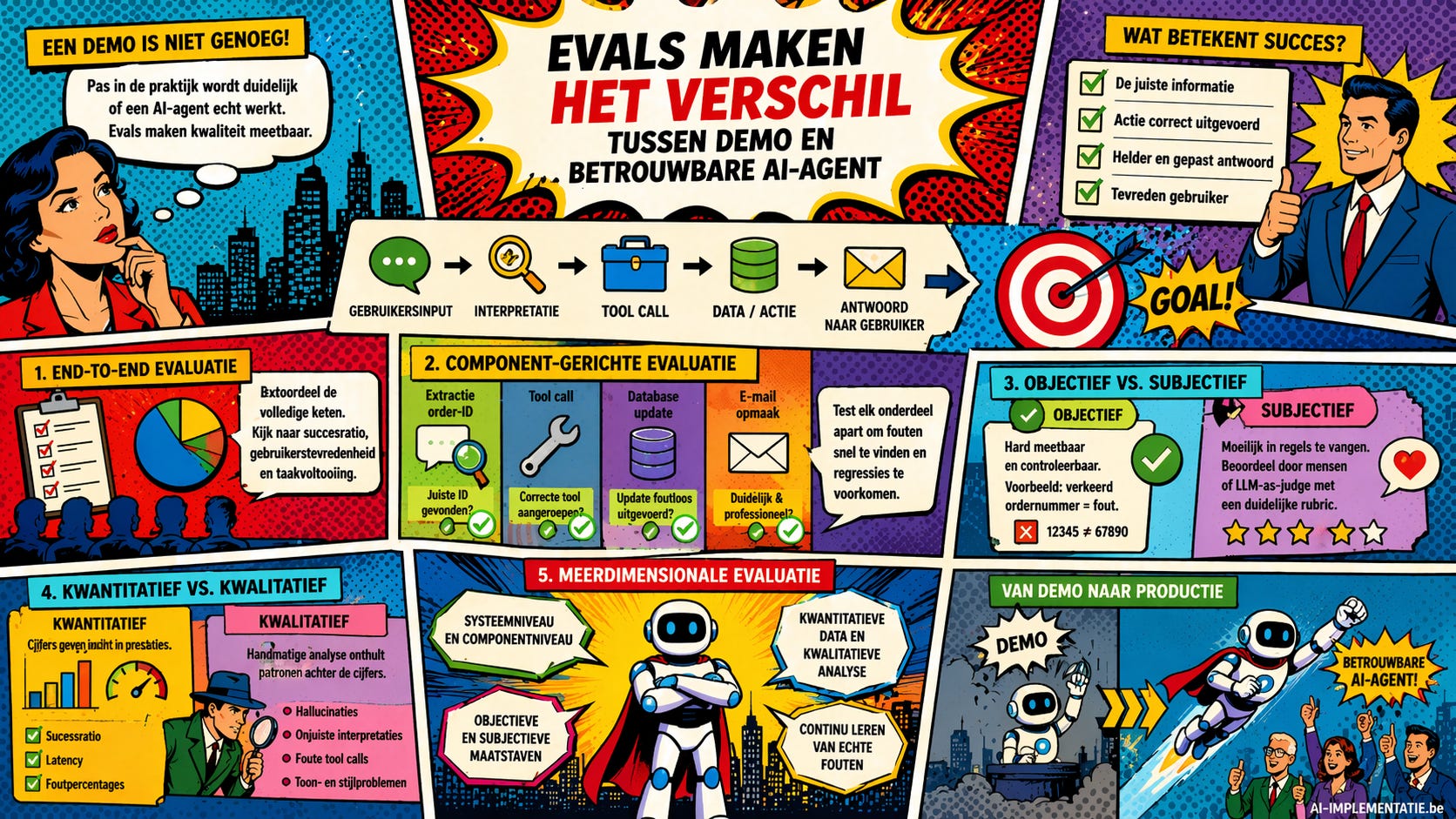
Van demo naar betrouwbare workflow
De opmars van AI-agents zorgt ervoor dat steeds meer bedrijven en organisaties experimenteren met geautomatiseerde workflows. Een model dat informatie ophaalt, een actie uitvoert en vervolgens een antwoord formuleert, lijkt al snel indrukwekkend. Toch zegt een geslaagde demo weinig over de betrouwbaarheid in productie. Zodra echte gebruikers, onvoorspelbare inputs en meerdere systeemstappen samenkomen, wordt duidelijk hoe kwetsbaar zo’n keten kan zijn.
Daarom zijn evals onmisbaar. Ze geven teams een gestructureerde manier om te meten of een agent doet wat hij moet doen. Zonder evaluatie blijft de kwaliteit vaak gebaseerd op buikgevoel of losse indrukken. Met evals ontstaat een veel concreter beeld: wat werkt goed, waar ontstaan fouten en welke onderdelen vragen bijsturing?
End-to-end versus componentniveau
Een eerste benadering is de end-to-end evaluatie. Daarbij kijk je naar de volledige workflow als één geheel. De vraag is dan niet hoe elke stap afzonderlijk presteert, maar of het eindresultaat voldoet. Heeft de gebruiker gekregen wat hij nodig had? Werd de taak correct afgerond? Is de algemene ervaring positief? Dat soort evaluaties is bijzonder nuttig, omdat het dicht aansluit bij de realiteit van de eindgebruiker. Tegelijk heeft deze aanpak een duidelijke beperking: wanneer de uitkomst slecht is, weet je nog niet automatisch waar het fout liep.
Precies daarom is componentgerichte evaluatie zo belangrijk. In plaats van alleen naar het eindresultaat te kijken, analyseer je elke bouwsteen van de workflow apart. Haalt het systeem het juiste ordernummer uit een bericht? Wordt de correcte databank aangesproken? Loopt een update goed door? En is de uiteindelijke communicatie naar de gebruiker helder en professioneel geformuleerd? Door die onderdelen los te testen, wordt foutopsporing veel gerichter. Problemen blijven dan niet hangen in een vaag gevoel dat “de agent niet goed werkt”, maar worden herleid tot een concrete stap in het proces.
Objectieve en subjectieve evaluaties
Binnen die evaluaties moet ook onderscheid worden gemaakt tussen objectieve en subjectieve criteria. Sommige fouten zijn eenvoudig en hard meetbaar. Wanneer een gebruiker een specifiek ordernummer opgeeft en het systeem koppelt dat aan de verkeerde bestelling, dan is dat gewoon fout. Zulke gevallen kun je relatief makkelijk testen met klassieke validatie, vaste regels of gecontroleerde datasets.
Moeilijker wordt het bij eigenschappen die minder zwart-wit zijn. Is het antwoord beleefd genoeg? Komt de toon professioneel over? Helpt het systeem de gebruiker echt vooruit, of blijft het hangen in vage formuleringen? Zulke vragen laten zich niet altijd vatten in een simpele ja-of-neen-test. Daarom worden hiervoor vaak menselijke beoordelaars ingezet, of modellen die op basis van een duidelijke beoordelingsrubric een antwoord evalueren.
Cijfers alleen volstaan niet
Ook het onderscheid tussen kwantitatieve en kwalitatieve evaluatie is cruciaal. Cijfers zoals succesratio, latency en foutpercentages zijn waardevol omdat ze trends zichtbaar maken. Ze tonen of een systeem sneller, stabieler of nauwkeuriger wordt. Maar cijfers alleen vertellen nooit het volledige verhaal. Handmatige foutanalyse blijft nodig om terugkerende patronen te herkennen, zoals hallucinaties, onduidelijke antwoorden, misverstanden in de interpretatie van gebruikersvragen of problemen in de toonzetting.
De belangrijkste les is dan ook dat evals nooit eendimensionaal mogen zijn. Een betrouwbare AI-agent vraagt om evaluatie op meerdere niveaus tegelijk. Je moet het volledige systeem beoordelen, maar ook de afzonderlijke componenten. Je hebt objectieve controles nodig, maar ook subjectieve beoordelingen. En je moet zowel naar meetbare prestaties als naar de onderliggende kwaliteit van interacties kijken.
Wie AI-agents serieus wil inzetten, kan evaluatie dus niet behandelen als een laatste controle achteraf. Evals horen thuis in het hart van het ontwikkelproces. Alleen zo wordt duidelijk of een agent niet alleen indrukwekkend oogt, maar ook echt klaar is voor gebruik in de praktijk.