
OpenAI maakt stemassistenten beter met drie nieuwe realtime-modellen
OpenAI heeft drie nieuwe spraakmodellen voor zijn API gelanceerd: GPT-Realtime-2, GPT-Realtime-Translate en GPT-Realtime-Whisper. De modellen moeten ontwikkelaars helpen om stemassistenten te bouwen die niet alleen natuurlijker praten, maar ook live kunnen redeneren, vertalen, transcriberen en acties uitvoeren terwijl een gesprek nog bezig is.
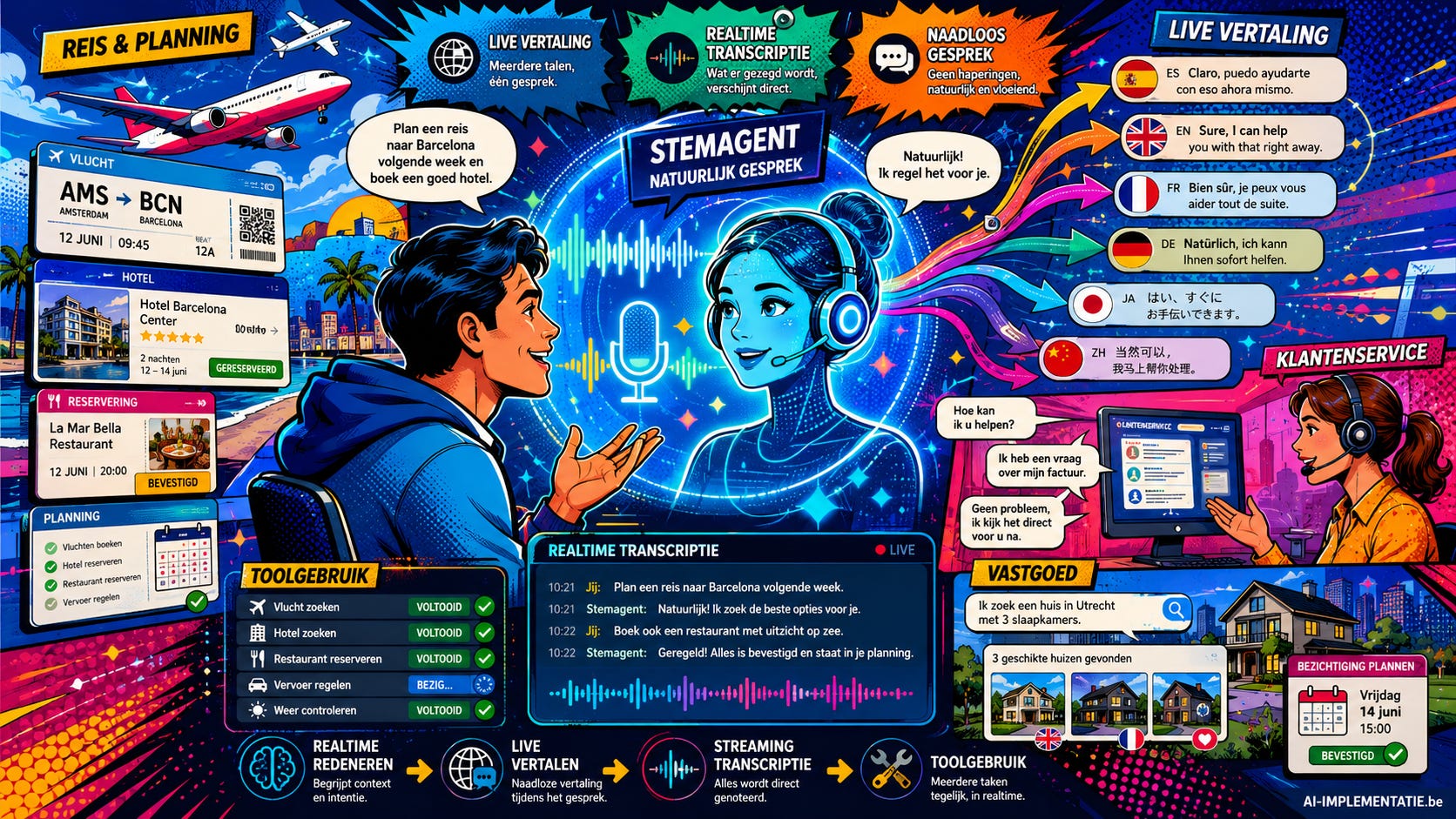
Een nieuwe bouwlaag voor spraakgestuurde AI
OpenAI zet een volgende stap in de strijd om de steminterface. Het bedrijf introduceerde op 7 mei 2026 drie nieuwe audiomodellen in zijn Realtime API: GPT-Realtime-2, GPT-Realtime-Translate en GPT-Realtime-Whisper. Samen vormen ze een bredere toolkit voor ontwikkelaars die spraakgestuurde AI-agents willen bouwen die verder gaan dan klassieke vraag-en-antwoordgesprekken.
De belangrijkste vernieuwing is GPT-Realtime-2. Volgens OpenAI is dit zijn eerste realtime-spraakmodel met redeneervermogen op GPT-5-niveau. In de praktijk betekent dat dat een stemagent complexere opdrachten moet kunnen begrijpen, context langer moet vasthouden en ondertussen tools kan gebruiken. Denk aan een reisassistent die niet alleen luistert naar een wijziging in je vlucht, maar meteen je hotelboeking controleert, alternatieven opzoekt en het antwoord hardop terugkoppelt.
Minder wachttijd, natuurlijkere gesprekken
Daarmee wil OpenAI af van het haperende karakter van veel huidige voicebots. Die werken vaak nog alsof een telefoongesprek uit losse beurten bestaat: de gebruiker praat, de bot wacht, denkt na en antwoordt pas daarna. GPT-Realtime-2 moet vloeiender omgaan met onderbrekingen, correcties en vervolgvraagstukken. Het model kan bovendien meerdere tools tegelijk aanroepen en met korte zinnen laten merken dat het bezig is, bijvoorbeeld door te zeggen dat het een agenda of reservering controleert.
Op benchmarkniveau claimt OpenAI een duidelijke sprong. Op Big Bench Audio, een test voor redeneervermogen bij modellen met audio-input, haalt GPT-Realtime-2 met hoge redeneerinstelling 96,6 procent tegenover 81,4 procent voor GPT-Realtime-1.5. Ook op Audio MultiChallenge, gericht op meerstapsdialogen en instructieopvolging in gesproken gesprekken, meldt OpenAI vooruitgang. Zulke cijfers zeggen niet alles over prestaties in chaotische echte omgevingen, maar ze tonen wel dat stem-AI sneller richting volwaardige agenten evolueert.
Live vertalen en transcriberen als extra wapens
De tweede nieuwkomer, GPT-Realtime-Translate, is gebouwd voor live spraakvertaling. Het model ondersteunt meer dan zeventig invoertalen en vertaalt naar dertien uitvoertalen terwijl de spreker nog praat. Dat maakt het interessant voor klantenservice, onderwijs, internationale meetings en mediaplatformen. Deutsche Telekom test het model bijvoorbeeld voor meertalige ondersteuning, waarbij klanten in hun eigen taal kunnen spreken terwijl de andere kant een live vertaling ontvangt.
GPT-Realtime-Whisper vult de reeks aan als streaming transcriptiemodel. Het zet spraak om naar tekst terwijl iemand spreekt, wat bruikbaar is voor live ondertiteling, vergaderverslagen, notities en workflows waarin gesproken informatie meteen verwerkt moet worden. Daarmee koppelt OpenAI zijn oudere Whisper-erfenis aan de realtime-infrastructuur van zijn nieuwere API-platform.
Van praatbot naar digitale werkassistent
Ook de eerste zakelijke toepassingen geven aan waar OpenAI naartoe wil. Zillow bouwt aan vastgoedassistenten die zoekcriteria kunnen begrijpen en acties zoals het plannen van bezichtigingen kunnen uitvoeren. Priceline ziet toepassingen in stemgestuurde reisplanning en Deutsche Telekom kijkt naar klantenservice over taalgrenzen heen. De modellen zijn beschikbaar via OpenAI’s Realtime API, met aparte prijzen voor audio-input, audio-output, vertaling per minuut en transcriptie per minuut.